Building and Applying Semantic User Contexts for Data Retrieval (#00004)
Selling points: Today's most popular engines for searching over large data sets (Google, Windows Find, etc.) are hopelessly inadequate in finding semantically related documents as specified by a search query. In truth, the first-cut model of brute-force keyword search didn't change much until Google introduced PageRank, which ranks webpages roughly by the # of times they are linked to in other websites. This goes a long way in determining the legitimacy of a website, but is still very far from gettting webpages that are still relevant to the original search query.
The lacking factor is human context. When I type in "apple" to Google (a common example cited when discussing web search), Google cannot possibly know whether I mean Apple Computer or Apple Sauce or Washington Apples or Apple Farmers. The interface of a search engine is inadequate to capture the precise concept that the user means to say when he types in keywords. A good search engine attempts to infer the context of the user to return webpages that will probably be a good match for the user. In the past, people have attempted to solve this problem in a variety of ways:
Change the interface of the search engine (to provide more context for the user to specify, so that he can be more specific)
Ask users to add metadata to webpages that help categorize them for web search using AI ontologies (see Tim Berners-Lee's work on the Sematic Web)
Attempt to infer properties about the web page based on data (information in links to the website, the title of the page, etc.) without user input. This is mentioned in part in Google's original prototyping paper.
As you might have already observed, the above list enumerates two problems that are being addressed:
How do I figure out what the user wants?
Once I have some representation of the user's desired subject matter, how do I rank webpages in order of relevance?
We are focusing on #2 in this document.
Considering the faults and design of search these days (heavily keyword based, with some tweaks to rank by relevancy) it is no surprise that web search is good for finding proper nouns (bill clinton), area-specific terms (algorithm invariant), and other queries where keywords capture most of the user's desired data (keyword in page ~= webpage will be in my desired data set). However web search will fail in situations like "fruit farmers in california" - websites that only talk about "apple farmers" will rank very low if the word fruit doesn't occur.
The solution to this problem is based on a simple idea - just a secretary slowly begins to understand the difference between what a boss means when he says "i need those briefs" and "i need my briefs", so must a search engine learn how its user categorizes data for subsequent searches. And really, he should be drilling down amongst a series of concepts. Consider the following example:
<User>: june buyers fremont
<Engine>: returns a keyword rank list with june buyers fremont (as google might), and a list of word clusters. "do you mean buyers june fremont clothes", "do you mean buyers june fremont food".
<User>: clicks a word cluster or refines the query
(repeats)....
As users begin to navigate and understand the word cluster space, we can record positive responses and adjust the word cluster database for future searches. This can be on an individual basis or user groups can share the same context. In addition, contexts can themselves be commoditized, as one group can use the context of another group for web search (i.e. enterprise contexts that are sold to all plastic companies). Since we plan to represent word clusters as a weighted directed graph, where words are nodes and clusters are formed from strongly connect subsets of the graph, we can also "compose" contexts together, with what I think would be interesting results.
What would we expect after long term user use? Here is a snapshot of what we might see, where we have denoted distance as a measure of weight. The farther away, the less weight something has:
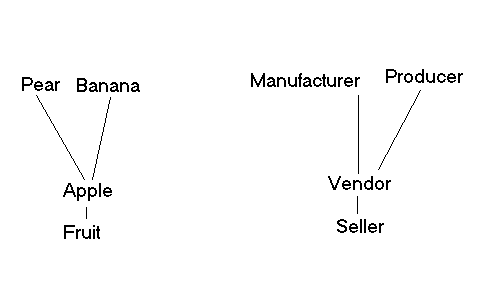
User query: Apple Vendor
Here we see that synonyms will be related, as will super sets (fruit is a superset of apple). So it is possible, although at a lower weight, to receive a page with banana seller, Since we are modeling the entire set of English words (and if we don't have a node in the graph, we default to keyword search), we can easily modify this with AI-like metadata later on as we standardize the relationship between words as a part of the query process i.e. restaurant <located in> california. There are a few reasons why this is a great approach to the search problem.
The user creates his own search space, and his own weights. Over time, this begins to reflect the context he adds along with his keyword searches.
Since the search algorithm also helps the user navigate the word cluster space, the user also begins to understand how to formulate queries so that he can get to results faster.
How the algorithm might work:
Since we already have an implementation for the data representing the user's context, we only need a way to specify the weights of the edges, and also to adjust these weights in response to user feedback. Here is a simple first cut algorithm that may go aways in demonstrating how this might be done.
We structure the graph so that the sum of all weights exiting a particular node is 1. The weight between two nodes i and j, can then be said to represent "how often (in %) the user means word j when he specifies word i". This can also be used to compute correlations that are several edges away from a node to start making clusterings. As a simple example, clusterings can be developed by removing all edges with a weight less than 5%. A cluster for keyword i can be considered either the strongly connected subset that includes i of this derived graph, or even the set of all nodes that are reachable from i in this derived graph. As such, if we find word j, with keyword i, we can place that webpage higher in rank with weight proportional to the product of all paths leading from i to j.
When a user says that webpage W satisfies his web search, we look for other words in the webpage close to the query word, and also in the title, metadata, etc. that can help us relate that word with other words in the page. (So far this is pretty weak, but I think that there is a solution to this problem, I need to think about it).
Prior Art Research: TODO
Patent Filing Documents: TODO